
Traditionally, HTML text files only contained ASCII characters, as represented by the codes from 0 to 127. Fortunately, most modern Web browsers can display all the codes up to 255, as well as higher-numbered Unicode characters, although the results can be inconsistent on older computer platforms that use their own character set.
Although older browsers may let you choose a specific character set, some characters may be rendered incorrectly. Worse still, the fonts on some platforms can lack a few of the necessary characters.
For these reasons it’s common practice to avoid using codes from 128 to 255. Having said this, you can force a browser to use a given character set by including a meta tag in the head of a page, such as:-
which indicates that the ISO 8859-1 (Latin-1) character set is to be used. Other character sets can be imposed using other content values, such as text/html;charset=x-mac-roman for the Mac OS Roman character set or text/html;charset=windows-1252 for the Windows 1252 set.
meta tag isn’t provided the recipient can select any character set, although if a tag is present, the user’s selection is ignored. Unfortunately, some browsers give the impression that your chosen character set is in operation, when in fact it’s set by the meta tag in the page.Understandably, some Mac OS browsers can’t display characters that aren’t part of the Mac’s character set, while others show them badly, often in the form of bitmap images. These include the following:-
In theory, the character set problem is solved by encoding non-ASCII characters as a special string of characters known as an HTML entity. In reality, some browsers don’t understand every entity.
The following table shows several ways in which a ® (registered trade mark) can be represented:-
| Entity Type | Entity |
|---|---|
| Named | ® |
| Decimal Character Code | ® |
| Hex Character Code | ® |
As you can see, an entity starts with & (ampersand) and ends with ; (semicolon). Although some browsers accept entities without semicolons, they must be included to ensure compatibility.
Named entities are easy to understand when viewing the source of HTML code and are accepted by most browsers. Unfortunately, they don’t always work in older browsers. For example, Netscape 4.7 doesn’t recognise the following named entities and shows them as a character string:-
A character code uses a number assigned to the character instead of a name and is suitable where content is automatically generated, or for non-Western languages where named entities have no meaning. They can also be used for characters without a named entity, such as the codes from 128 to 159, which are outside the ISO 8859-1 (Latin-1) character set. Unfortunately, some older browsers don’t understand every character code, especially those in hexadecimal (hex) form.
Since the & (ampersand) identifies the start of each entity it must itself be presented as an entity when used in the contents of a Web page, even though it’s a standard ASCII character. This means that the text three pounds & ten pence must be entered into a page as:-
In fact, all the special ASCII characters used in HTML are best encoded, as shown below:-

" (double quote) when used as part of the text in a page. This is wrong, since double quote marks are reserved for enclosing the values inside tags.% (percentage sign) followed by the ASCII code of the character in hex. Hence &file 1.gif must be represented as %26file%20.gif.The tables in this section give details about the entities used for common characters. The links below show how your browser should represent some of the more usual codes.
Although most browsers accept most of the codes in the first two groups, some don’t accommodate those characters that use higher codes. Codes not included in the above are commonly used for non-Roman languages.
These raw HTML codes can be used to force a browser to use specified characters. Most of these entities are very rarely used, apart from the special cases described above. The remaining characters don’t have a named entity so you must use numerical codes to represent them.

According to the ISO 8859 1 (Latin-1) standard these values are not assigned to characters that can be displayed, meaning they shouldn’t be used for characters in HTML. In reality, the codes shown in the following table are widely recognised and correspond to codes in the Windows character set. Note that these characters don’t have named entities, which means only numerical codes can be used. Once again, the characters shown in the Char column are as interpreted by your browser, so they may appear differently to the intended character detailed in the Description column. In fact, some browsers don’t show any of these characters, instead displaying a ? or a keyboard button symbol.

* Similar characters available in codes 256 to 912
• Similar characters available in codes 8192 to 12287
In theory, it’s preferable to use the codes for the similar Unicode characters that appear later in this document. Unfortunately, some older browsers simply don’t support these newer codes and even the behaviour of browsers with older codes can be unpredictable.
The ISO 8859 1 (Latin-1) characters are used in languages that employ a Roman or Latin script, as in most of western Europe and other western countries. Name or code entities can be used.
Unfortunately, the following Mac OS characters, as well as the standard Apple symbol, aren’t available in the Latin-1 set:-
The Latin-1 set, as shown below, is also part of the Unicode standard, although many browsers don’t recognise the less common, showing instead a ? or a keyboard button symbol. The first block of characters are mainly concerned with punctuation and internationally-recognised symbols:-

The next set consists of accented or special uppercase characters:-

while the final group contains special or accented lowercase letters:-

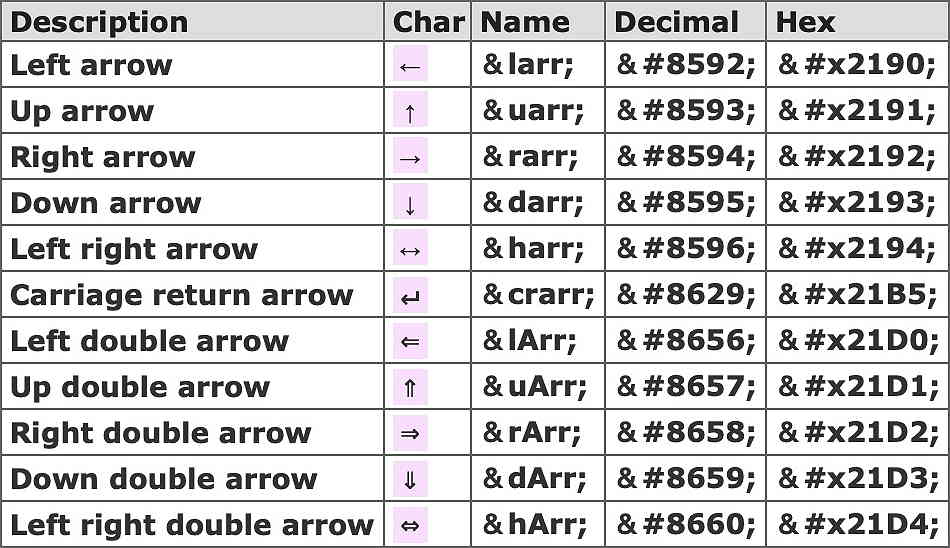
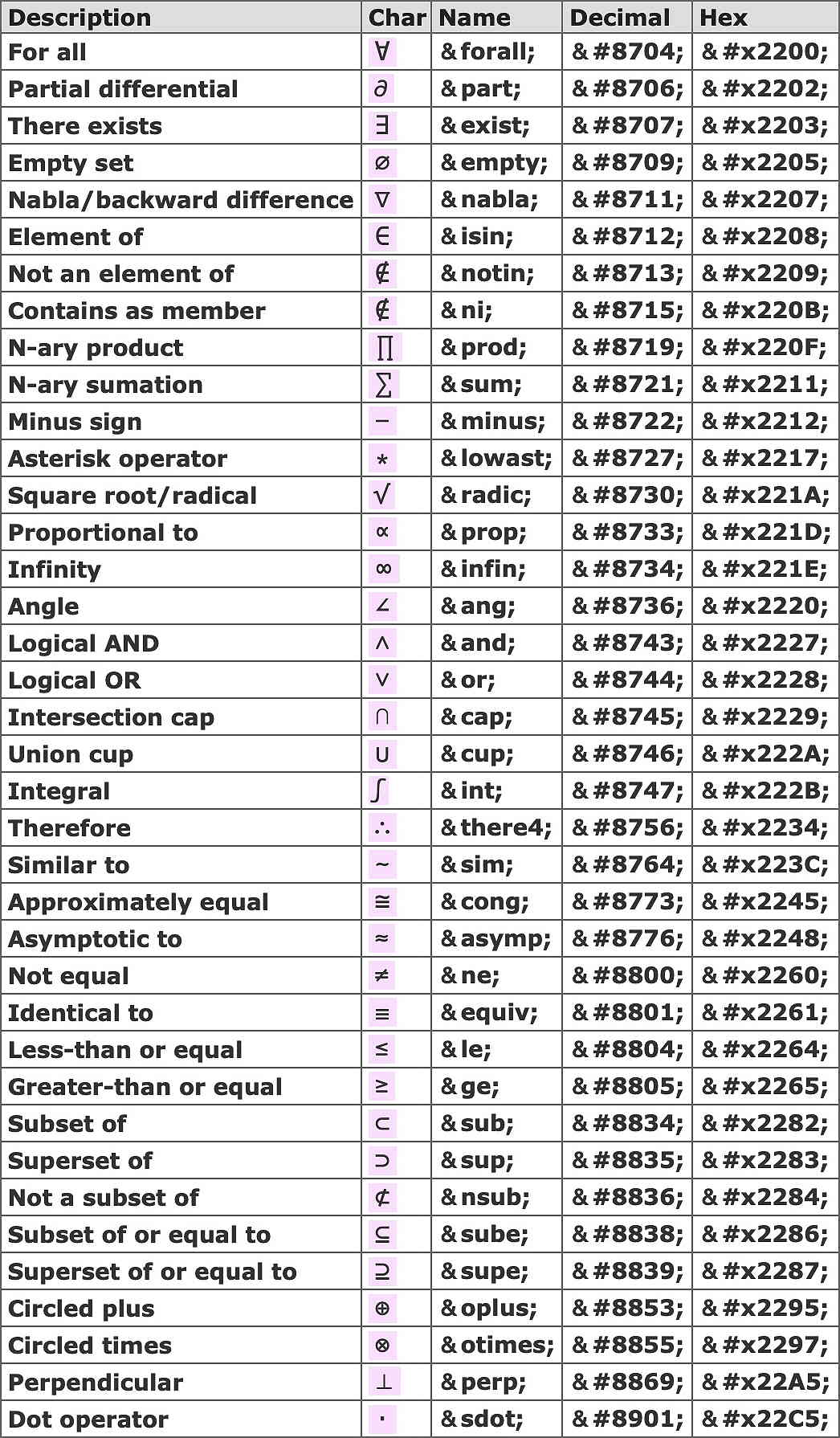
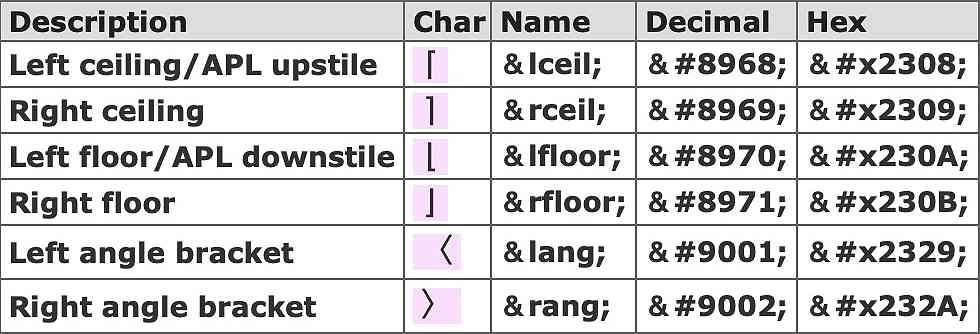
These entities correspond to modern Unicode character assignments, the most useful being:-

These characters, as used in mathematics, aren’t supported by some older browsers.

These codes replicate many of the items contained in codes 128 to 159. although some browsers don’t support these newer codes, meaning that some of the older codes are still used.



• Click here to see an extensive list of Unicode character codes.
• The entire list of Unicode characters can be found at www.unicode.org/charts/.
©Ray White 2004.