 Speech Synthesis in the Classic Mac OS
Speech Synthesis in the Classic Mac OSBy tradition, most people use a keyboard and a display screen to communicate with a computer. However, this is really an alien way of working, especially for anyone who has a physical disability. Fortunately, two mechanisms can be used to ease the conveyance of information: speech synthesis, in which the computer converts textual data into audible speech, and speech recognition, where the user dictates text or gives spoken instructions to the machine.
Speech synthesis is of little use to those who don’t suffer from sight defects, although it can be a useful aid during proof reading. And speech recognition, although clever, isn’t a great boon to those that can use a keyboard or any other kind of pointing device. Also, having overcome the embarrassment of speaking to a machine, you’ll find that spoken text isn’t always easy to read and may need extensive editing, at which stage many people revert to using a keyboard.
Speech Synthesis in the Classic Mac OSThe Classic Mac OS can use its Text-To-Speech (TTS) mechanism to convert the text within documents and dialogues into audible speech.
To use TTS, your Extensions folder, which is inside the System Folder, must contain the Speech Manager file, at least one version of the MacinTalk files and a Voices folder, the latter with appropriate voice files. Also, the Speech control panel must be in the Control Panels folder.
 The MacinTalk Synthesisers
The MacinTalk SynthesisersFour different speech synthesisers can be used, matching the files in your Extensions folder:-
This original form of MacinTalk isn’t supported by modern versions of the Mac OS.
Suitable for any Mac with a 68000, 68020 or 68030 processor running at under 33 MHz. Note that even if you use Macintalk 3, you’ll need the MacinTalk 2 synthesiser file to use any MacinTalk 2 voices. This synthesiser’s voices, such as Boris and RoboVox, only use a small amount of RAM.
An improved version of MacinTalk, designed for 68030 machines running at 33 MHz or more.
For 68040 or PowerPC-based machines only. Each voice associated with this synthesiser, such as Agnes, Bruce and Victoria can use over 5 MB of RAM. Since they’re mainly contained in system memory you don’t need to adjust the memory assigned to speech applications, but sufficient memory must still be available. Some voices are compressed to reduce the memory requirements.
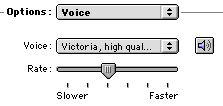
This panel sets the defaults for speech synthesis. As shown below, you can choose the preferred Voice and Rate of delivery, and then click on the loudspeaker box to hear a sample.
The Talking Alerts options, as shown below, allows the system to speak whenever a warning dialogue box appears. You should enable the Speak the phrase checkbox and select a phrase if you want a standard message spoken in all dialogues. Fortunately for everyone’s sanity, talking alerts come to an immediate stop whenever you hit a key or click the mouse.

The use of TTS in SimpleText is illustrated below. To speak the text you simply select Speak All in the menu. And, if you wish, you can choose an alternative voice for the application.

Some applications let you modify the voice parameters, as in this dialogue used in So To Speak (Eric Weidl), a neat program that demonstrates the full abilities of TTS:-

As you can see, this application includes adjustments for Modulation, which changes the inflection of the voice for emphasising parts of words or sentences, Pitch, the underlying tone of the voice, which is usually higher for females, and Rate, the speed of delivery, as found in the Speech control panel.
You can also select options such as Literal for Characters and Numbers, which means that the voice reads out each character or number individually. In this particular application, you can also use a Text Input in the form of Phonemes (see below), providing a more exact control over the voice.
Some applications also indicate the Gender of the voice, which in this instance is female, and the Age of the speaker, which in this case is given as 35.
 Classic OS Speech Recognition
Classic OS Speech RecognitionThe speech recognition system used in the Classic Mac OS is known as PlainTalk. It lets you give verbal instructions to your computer, but only with an AV Mac or PowerPC-based machine.
The extensions required for PlainTalk add extra features to the Speech control panel. The Listening option, as shown below, lets you choose a special key combination that makes the computer listen. This prevents your machine from following verbal instructions that are meant for someone else.

If the key combination is used to toggle speech recognition you can choose whether or not to prefix your verbal instructions with a specific word, such as Computer. So instead of saying Open SimpleText you would have to speak the words Computer Open SimpleText.
The computer’s response to a spoken command is set in the Feedback part of the panel, as shown below. When recognition is activated, a graphical character appears, in this instance with the name of Connie. If Speak text feedback is selected, the character speaks back to the user. However, if a simple confirmation is required, you can select a system sound from the Recognized menu.

When speech recognition is enabled, a list of commands also appears in the Speakable Items entry in the Apple menu. These commands can be initiated from spoken instructions, but only after you’ve enabled them in the Speakable Items section of the Speech control panel, as shown below.

The Classic Mac OS doesn’t provide speech recognition within applications, which means you’ll have to buy extra software, such as ViaVoice (IBM), to put spoken material into your documents.
Recognising words spoken as computer instructions isn’t too difficult, since the machine already knows the range of commands that can be issued. Understanding real speech is a much greater problem. As in PlainTalk, the recognition software needs to know the current language and the associated scripting system, which for European-based languages is known as Roman.
The recognition process involves converting the digital signal derived from the microphone into a series of phonetic codes. The patterns in these codes can then be compared with the contents of a database containing patterns corresponding to recognised words in the specified language. When a known word is encountered the computer can effectively type the word into the front application.
Unfortunately, there are a couple of complications. Firstly, most languages also embrace a huge number of regional dialects. Usually, such variations involve differences in the pronunciation of vowel sounds, although some consonants can be modified or omitted entirely.
ViaVoice gets round the accent problem by a process of learning. As you train the application you simply correct each word that the software misunderstands. Gradually, as more and more words are corrected, the program adapts itself to your own style of pronunciation.
Words that sound the same but have different spelling, such as their, there and they’re, can also cause problems. These can often be fixed by looking at the context of the word or the associated grammar, as in the phrase There is a house, which can only begin with There. But this doesn’t always work, as in This is our Pete, which could also be This is our peat.
 Pronunciation Dictionaries
Pronunciation DictionariesAny speech synthesis system, including Apple’s TTS, will sometimes pronounce words incorrectly, especially those used for the names of people and places. TTS can accommodate such unusual words by using a pronunciation dictionary, also known as speech dictionary.
In the Classic Mac OS, each dictionary is stored in a resource, identified by the code dict, which is kept in the resource fork of a file. Any kind of document can contain a dictionary, including a speech application file, a self-contained dictionary file or a normal document.
dict or rsrc.The dictionary itself describes the pronunciation of each word using phonemes and prosodic controls, each of which is represented by a sequence of characters. Phonemes describe the sound of each syllable while prosodic controls add the stress and intonation for natural speech.
A phoneme is a component of speech, which, in the case of TTS, is represented by a case-sensitive symbol or a group of symbols. These symbols represent the sound of the component, irrespective of its usual spelling. For example, the common vowel shown in red in the table below for the words bout and how is normally represented by the AW phoneme.
The following phonemes are used for vowels:-
| Example | Example | |||
|---|---|---|---|---|
| AE | bat | IX | cloes | |
| EY | bait | AA | cot | |
| AO | caugt | UW | boot | |
| AX | about | UH | book | |
| IY | meet | UX | mud | |
| EH | bet | OW | boat | |
| IH | bit | AW | bout | |
| AY | bite | OY | boy |
while the following are used for consonants:-
| Example | Example | |||
|---|---|---|---|---|
| b | bin | N | tang | |
| C | chin | p | pin | |
| d | dark | r | ran | |
| D | those | s | satin | |
| f | fake | S | shin | |
| g | gain | t | tin | |
| h | hat | T | thin | |
| J | gin | v | van | |
| k | kin | w | wet | |
| l | limb | y | yank | |
| m | mat | z | zen | |
| n | knock | Z | genre |
The remaining two, shown below, are used for the spacing of phonemes.
| Phoneme | Meaning |
|---|---|
| % | Silence |
| @ | Breath intake |
By using the appropriate phonemes we can construct any word. For example, the word application, when written in phonemes comes out as AEplIHkEYSAXn.
Prosodic codes, sometimes known as prosody symbols, can be used to fine tune the pronunciation of phonemes by adding stress and intonation to the speech.
The following codes are used:-
| Meaning | |
|---|---|
| 1 | Primary Stress |
| 2 | Secondary stress |
| = | Syllable mark |
| ~ | Unstressed |
| _ | Normal stress |
| + | Emphatic stress |
| / | Pitch rise |
| \ | Pitch fall |
| > | Lengthen phoneme |
| < | Shorthen phoneme |
| . | Sentence final fall |
| ? | Sentence final rise |
| ! | Sentence final sharp fall |
| … | Clause final level |
| , | Continuation rise |
| ; | Continuation rise |
| : | Clause final level |
| ( | Start reduced range |
| ) | End reduced range |
| “ | Varies |
| ‘ | Varies |
| ” | Varies |
| ’ | Varies |
| - | Varies |
| & | No silence between |
The stress codes, such as 1 and 2, indicate which syllables should be emphasised. For example, the word anticipation could be expressed in the form:-
The = (equals), is a syllable mark, which breaks the word up into syllables, as shown here:-
The word prominence codes of ~ (tilde), _ (underscore) and + (plus) make it possible to stress a particular word, while the ‘true’ prosodic codes of / (forward slash), \ (back slash), > (greater than) and < (less than) can modify a phoneme to make a word more natural. Finally, a pause can be introduced by adding a , (comma), or, for a shorter pause, a ‘ (single quote mark).
If a speech application finds a word in the current dictionary, it uses the dictionary’s entry instead of the speech synthesiser’s standard conversion rules.
The working of a dictionary is best illustrated by looking at an application designed for editing such a resource, in this instance DictionaryEdit (Simon Fraser). The following screen shot show what you might see if you look inside a dictionary:-

The left-hand box contains each text entry in the dictionary. In this rather silly example, the word shakespeare has been replaced by The Bard of Avon, although most dictionaries actually use a variation of the original word. When the left-hand button is pressed the entered text is converted into phonemes and prosodic codes and appears in the bottom-right pane. The result can be heard by clicking the right-hand button, allowing the user to modify the codes as required.
Some applications, such as DictionaryEdit, let you edit the header of dictionary resource, although most users shouldn’t need to modify it. This is the kind of window you’ll see:-
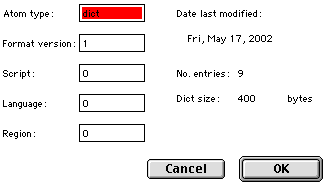
The following table shows the meanings of the entries:-
| Parameter | Notes |
|---|---|
| Atom | ‘dict’ |
| Format | ‘1’ |
| Script | ‘0’ |
| Language | ‘0’ |
| Region | ‘0’ |
| Date | Dictionary |
| Dict | Byte |
©Ray White 2004.
