 Inside a Database Application
Inside a Database ApplicationA database application lets you work on records, usually one at a time. Each of these records contains fields of textual or numerical data. The most common database application on the Mac OS is FileMaker Pro, although multipurpose programs such as AppleWorks can be used for simple tasks.
Inside a Database ApplicationA simple database consists of several records, each with a common number of fields that contain the information. This kind of document is also used in personal information manager (PIM) applications and can be transferred to a personal organiser or other hand-held device.
The example database shown below contains two records, each made up of six fields:-

Most applications let you create layouts, giving different views of the data and sometimes including graphics. In our example, only one record is displayed, complete with the field names for the fields. Each field contains formatted text (as shown in this example), a number, or a formula. The latter invokes a calculation that makes new text or numbers, usually from the content of other fields.
In AppleWorks, you can select Show Multiple from the Layout menu, as illustrated below:-
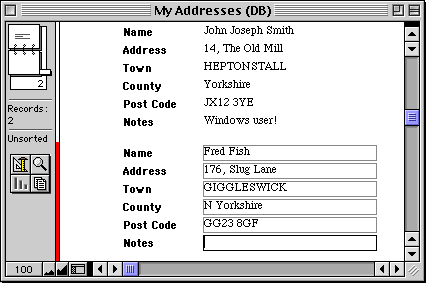
This lets you scroll through the records. As you can see, the second record has been selected and data is being entered. Some applications also provide a list view, as shown below:-

The presentation in this layout isn’t too elegant, although it gives a useful overview of the data. As shown here, you can click on a selected field to fully reveal its contents.
Most database applications let you select records manually or you can automatically select records that meet specific criteria, usually based on the contents of specific fields. You can also generate extra data from records that have been selected. For example, a summary calculation uses a formula to produce a value calculated from specific fields, but only in the selected records. A grand summary, on the other hand, uses a formula that works with chosen fields in all of the records.
The simple documents considered above are known as flat databases, since they contain a single set records. A relational database is more useful, since you can keep numerous sets of records, each of which is known as a table, and then set up relationships between the fields inside them.
Most businesses use databases of this kind. Typically, they’ll make a list containing customers details (table 1), a list of the invoices sent to customers (table 2), a list of suppliers (table 3) and a record of purchases (table 4). By relating these tables in an intelligent way they can generate all of the required documentation for the company’s operation, as well as producing the annual accounts.
The number of tables should be kept to a minimum, but without compromising effectiveness. In particular, any mutually dependent information, such as dates and week numbers, should be in the same table. If this isn’t done and the tables get ‘disconnected’ you could end up in a serious mess.
The most popular relational database application in the Mac OS is FileMaker Pro. The Developer version of this program can also be used to create a runtime application for use on a Mac or PC. This lets a user to view specific data without having to buy the FileMaker Pro application.
 Databases and Spreadsheets
Databases and SpreadsheetsThe information contained in a flat database (or in one table of a relational database) is similar to that found in a spreadsheet. Although a database has several records, each with a given number of fields, a spreadsheet also has several rows, each containing a specific number of columns.
It’s often convenient to use a generic file (see below) to transfer data between a spreadsheet application and a database program. The relationship between the elements in these documents is:-
| Database | Spreadsheet |
|---|---|
| Record | Row |
| Field | Column |
Some applications add an extra first record or row that contains a field name or column header. This is useful for sorting out data that arrives in an inconvenient order and, when the transfer is complete, can be easily removed from the destination document. The following picture illustrates what happens when the database file shown earlier in this document is transferred into a spreadsheet:-

Most database applications use a specific file format that’s only understood by the one program. However such files can be opened in other applications if you have a suitable file translator.
If you can’t find a file translator you can use generic files, as listed below in order of preference. Note that all of these files are also used in many spreadsheet applications. The filename extensions and Classic Mac OS type codes are shown for completeness.
.sk/.slk/.syk/.syl/.sylk TEXTSYLK retains formatted text, numbers and formulae, as well as widths and cell alignments for spreadsheets. Many spreadsheet applications support it, including Excel, Resolve and Wingz.
.dbf F+DBThis kind of file, created by dBase II, dBase III and other applications, conveys unformatted data. It can be converted to a CSV file (see below) for transferring to other database applications or Excel.
If you examine the contents of a DBF using a text editor you’ll discover that it contains dBase field types, which are defined as follows:-
| Field | Contents |
|---|---|
| C | Character |
| N | Numeric |
| D | Date |
| L | Logic |
| M | Memo |
.dif TEXTThis format is used for unformatted data. It’s employed on PCs, in the original AppleWorks, as used on the Apple II computer, and in the VisiCalc application.
.ldif/.ldi TEXTA special format used by Netscape for storing any number of contacts. Within the file, each element of information is prefixed by a description, as shown in this example:-
dn: cn=Fred Bloggs
objectclass: top
objectclass: person
objectclass:
objectclass: inetOrgPerson
objectclass:
givenName: Fred
sn: Bloggs
cn: Fred Bloggs
modifytimestamp: 0Z
telephoneNumber: 0200 123
homePhone: 0200 456
facsimileTelephoneNumber:
homePostalAddress:
mozillaHomePostalAddress2:
mozillaHomeLocalityName:
mozillaHomeCountryName:
dn: cn=Carol Bloggs
objectclass: top
objectclass: person
objectclass:
objectclass: inetOrgPerson
objectclass:
givenName: Carol
sn: Bloggs
cn: Carol Bloggs
modifytimestamp: 0Z
homePostalAddress:
mozillaHomePostalAddress2:
mozillaHomeLocalityName:
.txt/.tsv/.tdf/.tab TEXTThis kind of file, also known as tab delimited text or tabbed text only conveys unformatted data. Any non-ASCII characters and line endings must be corrected for use on other computer platforms.
When viewed in a text editor the content of this kind of file will look something like this:-
John Joseph Smith<HT>
14, The Old Mill<HT>
HEPTONSTALL<HT>
Yorks<HT>
JX12 3YE<HT>
Windows user!<CR>
Fred Fish<HT>
176, Slug Lane<HT>
GIGGLESWICK<HT>
N Yorks<HT>
GG23 8GF<HT><CR>where <HT> indicates a HT (Horizontal Tab) control code and <CR> represents a CR (carriage return). As you can see, a tab is used to delimit each field and a CR is used to mark the end of a record.
HT or CR characters..txt/.csv TEXTThis kind of file is similar to a TSV file (see above), except that a , (comma) is used as a delimiter. Unfortunately, this means that commas can’t be used in the entries themselves, which is highly inconvenient, especially for those countries that use a comma as a decimal point.
When viewed in a text editor the content of this kind of file looks something like this:-
John Joseph Smith,
14 The Old Mill,
HEPTONSTALL,
Yorks,
JX12 3YE,
Windows user!<CR>
Fred Fish,
176 Slug Lane,
GIGGLESWICK,
N Yorks,
GG23 8GF,<CR>which shows each field delimited by a comma and the CR used to mark the end of each record.
CR characters..vcf TEXTUnlike other database files, this format, which is accommodated by applications such as Address Book (Apple), Entourage (Microsoft) and Now Contact, can store data for a single contact or multiple contacts. It includes work and home addresses, several phone numbers, e-mail addresses and URLs, the time zone, a photograph and an audio clip, the latter often used to assist in the pronunciation of the name.
Some older applications use a separate vCard for every contact, sometimes preventing you from exporting or importing contact details in this format. However, you can usually drag contacts from such an application’s window to the desktop, which creates a file for each of the selected items.
 PIM Data Transfer
PIM Data TransferA personal information manager (PIM) is a special application that lets you store information about your contacts and appointments. These two sets of data (as well as other records) are kept in separate flat databases, although a cross-referencing facility is usually provided. Most programs also have the ability to transfer this information to a personal organiser or other hand-held device.
When transferring data between word processing applications, databases software and the separate databases in a PIM you’ll often encounter unexpected results. Here are a few hints:-
Sadly, the number of fields and their order isn’t standardised between PIMs, although you shouldn’t have any problems when transferring information via the vCard format (see above). With other files you have to juggle the fields to suit, often via a special dialogue similar to that shown below:-

In this instance, the first record in the imported file, as shown, contains the field names. This record, sometimes known as a header, makes it easy to align the data to the correct fields in the destination application. If such a header missing, or you hit one of the Scan Data buttons, you’ll see something like this:-
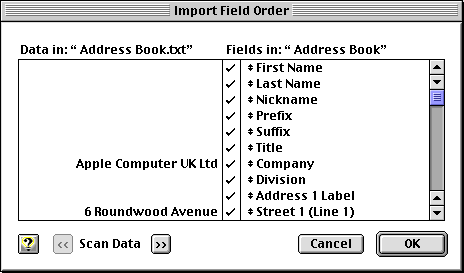
which is much more difficult to work with. Worse still, not all applications remember the dialogue’s settings, requiring you to repeat this process every time you transfer a different yet similar set of data.
Transferring data via a tabbed text file is often very easy, although it gets harder wait an increasing number of fields. Ideally, your source application should produce a header: some applications can do this automatically, whilst in others you must create it yourself. To do this, simply make a new record with a First Name of something like AAA_First_Name, a Last Name of AAA_First_Name and a Company Name of AAA_Company_Name. Now fill in all the remaining fields, using the field name itself for each field, so that, for example Address 1 contains the text Address_1, and so on, whilst any fields that you really don’t require can be filled with an x. Finally, sort your records by your preferred name and export the information as tabbed text. Now, when you open the file in your destination application, you can see exactly which field is which.
Sometimes you’ll encounter a destination application that doesn’t let you easily move the fields around or that objects to an excessive number of fields. To fix this problem, you should first export the data with a header, as described above, ensuring that any unwanted fields in the header record contain an x. Then open the tabbed text file in a spreadsheet application, such as Excel, or in the spreadsheet environment of AppleWorks, which should reveal all of your data with the header record at the top. You can then remove any unwanted columns, which correspond to the data in particular fields. Having modified the file, save it again as a tabbed text file and then import it into the destination program.
Some database applications create additional information in each record, this being computed from data in other fields. Unfortunately, this material isn’t usually sent with the rest of the data into a tabbed text file. One example, which appears as Full Name or Display Name in many PIMs, is normally generated in the application by concatenating the First Name to the Last Name, with a space in between. This means that the Full Name box in the destination application often ends up empty, requiring you to type the name by hand or to copy the required data from other boxes. This problem can also be fixed by passing the data through a spreadsheet application, as described above, but in this instance you must add an extra column and then enter, for example, Full_Name in the top cell. In the cell below this you must enter a suitable formula, such as =CONCAT(A2;" ";B2), which should give the correct full name for the first entry. Now select the remainder of the column and choose Fill Down, after which the rest of the names should appear. You can now transfer the data as normal.
The following tables refer to the contact fields in older PIMs, showing the field order from left to right and top to bottom. They illustrate the kind of variations that you can encounter.
| TouchBase PRO | ||
|---|---|---|
| Salutation | First | Middle |
| Last | Company | Title |
| Address | Address | City |
| State | Zip | Country |
| Work | Home | Fax |
| Custom | Custom | Custom |
| Custom | Custom | Custom |
| Custom | Custom | Date |
| Date | Custom | Custom |
| Custom | Custom | Marked |
| Modified | Notes | |
| TouchBase 2 | ||
|---|---|---|
| Salutation | First | Last |
| Company | Title | Address |
| Address | City | State |
| Zip | Country | Work |
| Home | Fax | Custom |
| Custom | Custom | Custom |
| Custom | Date | Date |
| Modified | Custom | Custom |
| Marked | Notes | |
| Address Book Plus | ||
|---|---|---|
| Prefix | First | Last |
| Suffix | Title | Company |
| Dept | Address | City |
| State | Zip | Country |
| Remarks | Phone | Work |
| Phone | Home | Phone |
| Fax | Phone | Car |
| Custom | Custom | Custom |
| Category | List | Revised |
| Entry | ||
| Dynodex | ||
|---|---|---|
| Business | First | Last |
| Title | Address | City |
| State | Zip | Country |
| Office | Phone | Home |
| Phone | Fax | Phone |
| Auto | Phone | Notes |
| Dept | Keyword | Birthday |
| Modify | First | |
Various different kinds of calender fields are also used, as shown in these examples:-
| Alarming | ||
|---|---|---|
| Date | Time | Subject |
| Notes | Type | Duration |
| Advance | Re | Re |
| Re | ||
| DateBook | ||
|---|---|---|
| Date | Start | End |
| Summary | Descriptn | Category |
| Type | Priority | Completed |
| DayMaker | ||
|---|---|---|
| Text | Start | Start |
| Finish | Finish | To Do |
| Done-Undone | ||
| Easy Alarms | ||
|---|---|---|
| Date | Start | Message |
| Advance | Recurrence | |
| First Things First | ||
|---|---|---|
| Text | Priority | Done |
| Category | Date | Start |
| Recurrence | Reminder | |
| Advance | Type | |
| LapTrack/Timeslips | ||
|---|---|---|
| Text | Start | End |
| Title | Description | Type |
| Done | Category | |
©Ray White 2004.
