
Although future computers will undoubtedly use Unicode, most machines continue to muddle along with 8-bit coding, allowing a maximum of 256 characters in each character set. And in plain ASCII text files, 7-bit coding is used, restricting the user to less than 128 characters.
Although different 8-bit coding systems are used on alternative computer platforms, most modern word-processing applications use a standardised character set within a proprietary document format, allowing files to be opened on any kind of machine. In fact, many Western applications use files that employ the ISO 8859-1 (Latin-1) character set, whatever computer is used.
Although a plain ASCII text file can be read on any computer, other text files should use the same character set as the recipient’s computer platform. If such files are incorrectly coded you’ll still be able to read the text, although many of the non-ASCII codes will give the wrong characters.
Minor differences in a character set can be corrected by repeated use of the find and replace feature found in most text editor applications. Alternatively, you can ‘fudge’ the problem by using special fonts. For example, if you want to read Windows documents on a Mac OS computer you can select a special font on the Mac OS machine that displays the Windows character set.
However, such messy solutions can be avoided by using special code conversion software. For example, the Classic Mac OS incorporates Apple’s Text Encoding Converter (TEC) mechanism, which is available to conversion utilities such as Cyclone (Tomasz Kukielka). You can also obtain special conversion software for Windows and other computer platforms.
Unfortunately, the following characters in the Latin Mac OS character set, as well as the standard Apple symbol, aren’t available in the 8-bit Windows 1252 or ISO Latin-1 sets:-
During code conversion such characters are often replaced by alternative symbols, such as ? (question mark) or _ (underscore). In some instances, the offending symbol is replaced by a similar ASCII character or a special string inside angle brackets, such as <pi> in place of the ‘pi’ character.
The following table shows how non-ASCII codes are converted when translating Mac OS text into the Windows format:-
| Mac | Win | Mac | Win | Mac | Win |
| 128 | 196 | 129 | 197 | 130 | 199 |
| 131 | 201 | 132 | 209 | 133 | 214 |
| 134 | 220 | 135 | 225 | 136 | 224 |
| 137 | 226 | 138 | 228 | 139 | 227 |
| 140 | 229 | 141 | 231 | 142 | 233 |
| 143 | 232 | 144 | 234 | 145 | 235 |
| 146 | 237 | 147 | 236 | 148 | 238 |
| 149 | 239 | 150 | 241 | 151 | 243 |
| 152 | 242 | 153 | 244 | 154 | 246 |
| 155 | 245 | 156 | 250 | 157 | 249 |
| 158 | 251 | 159 | 252 | 160 | 134 |
| 161 | 176 | 162 | 162 | 163 | 163 |
| 164 | 167 | 165 | 149 | 166 | 182 |
| 167 | 223 | 168 | 174 | 169 | 169 |
| 170 | 153 | 171 | 180 | 172 | 168 |
| 173 | 141 | 174 | 198 | 175 | 216 |
| 176 | 144 | 177 | 177 | 178 | 143 |
| 179 | 142 | 180 | 165 | 181 | 181 |
| 182 | 240 | 183 | 221 | 184 | 222 |
| 185 | 254 | 186 | 138 | 187 | 170 |
| 188 | 186 | 189 | 253 | 190 | 230 |
| 191 | 248 | 192 | 191 | 193 | 161 |
| 194 | 172 | 195 | 175 | 196 | 131 |
| 197 | 188 | 198 | 208 | 199 | 171 |
| 200 | 187 | 201 | 133 | 202 | 160 |
| 203 | 192 | 204 | 195 | 205 | 213 |
| 206 | 140 | 207 | 156 | 208 | 173 |
| 209 | 151 | 210 | 147 | 211 | 148 |
| 212 | 145 | 213 | 146 | 214 | 247 |
| 215 | 215 | 216 | 255 | 217 | 159 |
| 218 | 158 | 219 | 164 | 220 | 139 |
| 221 | 155 | 222 | 128 | 223 | 129 |
| 224 | 135 | 225 | 183 | 226 | 130 |
| 227 | 132 | 228 | 137 | 229 | 194 |
| 230 | 202 | 231 | 193 | 232 | 203 |
| 233 | 200 | 234 | 205 | 235 | 206 |
| 236 | 207 | 237 | 204 | 238 | 211 |
| 239 | 212 | 240 | 157 | 241 | 210 |
| 242 | 218 | 243 | 219 | 244 | 217 |
| 245 | 166 | 246 | 136 | 247 | 152 |
| 248 | 150 | 249 | 154 | 250 | 178 |
| 251 | 190 | 252 | 184 | 253 | 189 |
| 254 | 179 | 255 | 185 |
With suitable software, you can convert 7-bit or 8-bit material into Unicode format or convert 7-bit data into 8-bit format. However, converting Unicode material to 8-bit form or converting 8-bit material down to a 7-bit set is far trickier, since there aren’t sufficient codes to represent all the characters.
Fortunately, if the material is suitable for presentation on a Web browser, you can convert the text into HTML form. Then, assuming the conversion software works properly and you have a modern browser, you should see most characters correctly. Unfortunately, some older browsers don’t recognise all HTML entities or character codes, so some characters can still look wrong.
If you can’t use HTML, you’ll have to resort to using alternative characters or a string of characters to replace some of the original Unicode or 8-bit characters. The following table shows the standard Latin-1 character set, complete with the non-standard codes that exist between 128 and 159:-
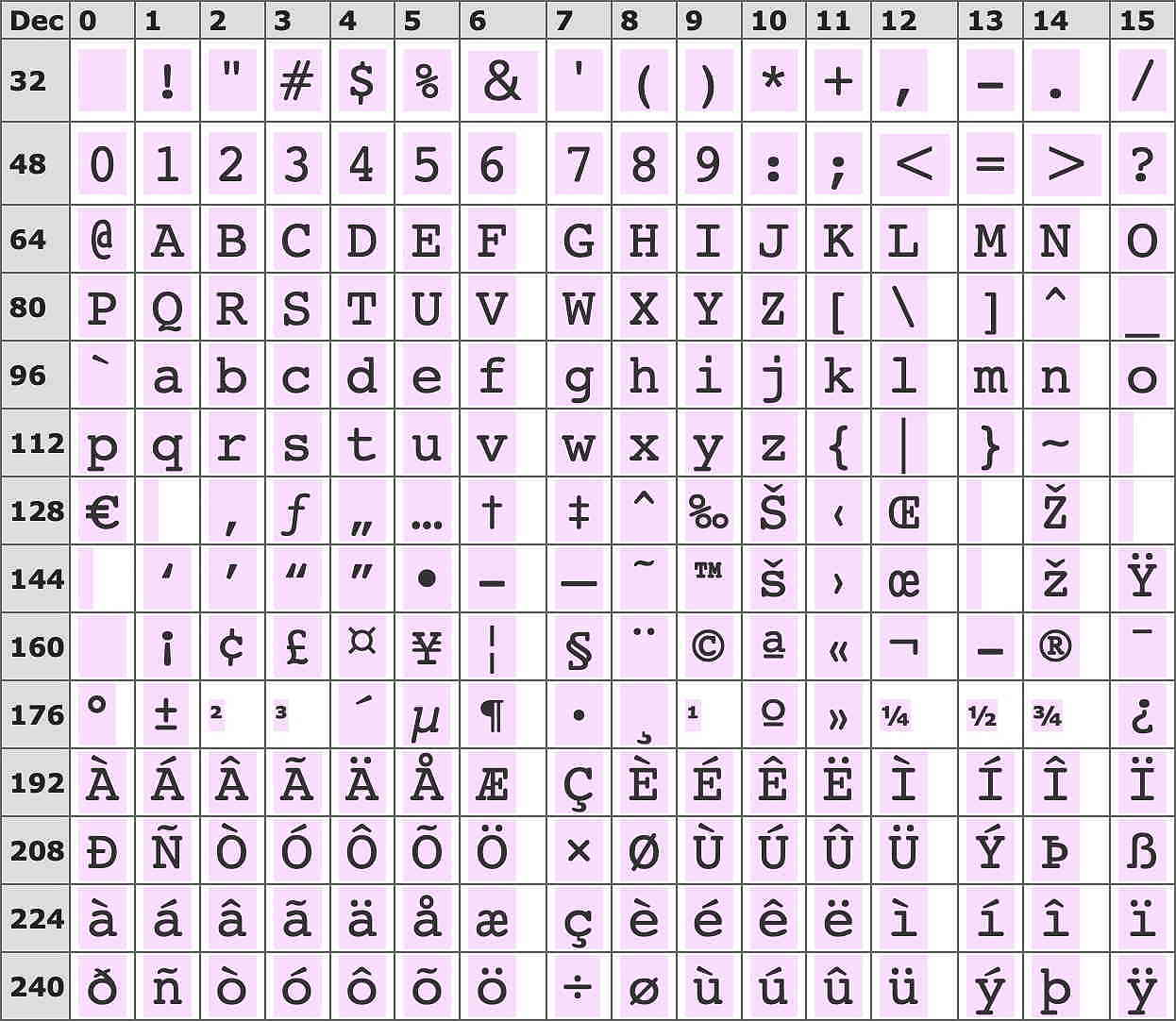
Those characters outside the normal ASCII character set can be replaced as follows:-
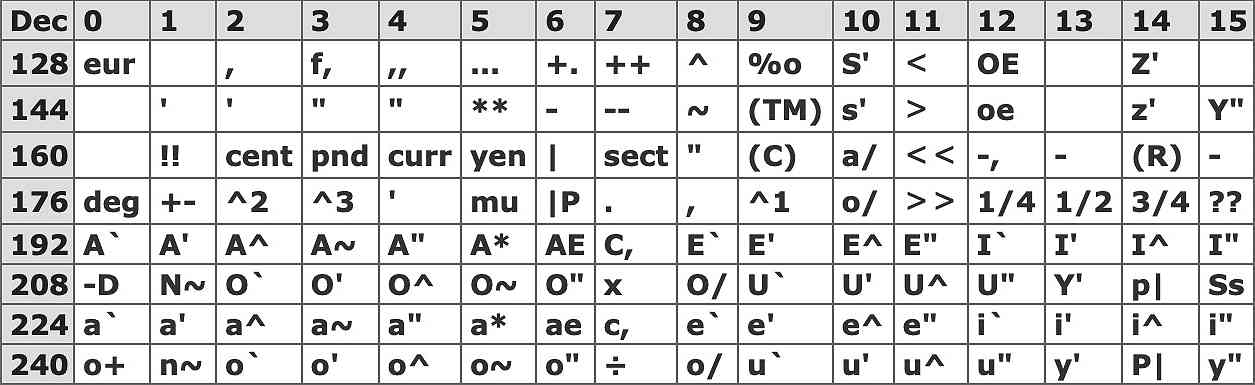
Such replacements avoid loss of information, although some characters can be ambiguous.
*bold* and text in italic could be written as _italic_.Special characters in the Mac OS character set can also be replaced, as in the suggestions shown below:-
| Character | Replacement |
|---|---|
| ≠ | /= |
| ∞ | o=o |
| ≤ | <= |
| ≥ | >= |
| ∂ | delta |
| ∑ | Sigma |
| ∏ | Pi |
| π | pi |
| ∫ | Int |
| Ω | Omega |
| √ | v/ |
| ≈ | ~= |
| ∆ | Delta |
| ◊ | <> |
| fi | fi |
| fl | fl |
| Apple |
| ı | <1> |
Different computer platforms use different codes for a line break, also known as a line ending or end-of-line (EOL). Most systems employ either the CR (carriage return) or LF (line feed) codes or a combination of both, as shown below:-
| System | End of Line |
|---|---|
| Mac OS • | CR |
| MS-DOS | CR followed by LF |
| UNIX | LF |
| VAX | CR followed by LF |
CR shouldn’t be confused with a soft return, which is produced when you press Shift-Return in the Mac OS.CR or LF as a space, creating a new line only when a <br> tag is encountered.Early computer systems could only store a specified number of characters in each line. Indeed, many machines used punched cards that held a maximum of 80 characters, corresponding to a line of text in a fixed-width window. Hence a line break was inserted at the end of every visible line of text.
Nowadays, text isn’t stored in chunks of a fixed size and can automatically wrap within a chosen size of viewing window. Although this removes the some of the presentational control provided by fixed line breaks, it allows the break characters to usefully separate paragraphs of text. In fact, in the Mac OS, a CR code is often represented by a ¶ (paragraph symbol).
Unfortunately, material from the Internet or a PC often has a line break at the end of every line. This means that you can end up with both a hard wrap, provided by the line break characters, and a soft wrap, provided by automatic wrapping in the window. This causes the the text to appear as a series of broken lines, varying with the width of the window.
If you encounter this problem, you’ll need a special utility to remove the unwanted line breaks. This should remove breaks within a paragraph whilst ensuring that the breaks used for separating paragraphs are kept in place. Ideally, it should also remove any unwanted spaces from the text.
©Ray White 2004.
