
Most of the 8-bit character sets described below are obsolete or rarely encountered. However, this information can be useful for converting older documents into a modern format.
This set is used in the original IBM PC and is also known as the ANSI character set. It uses codes from 128 to 168 for world trade characters, whilst the remaining codes are used for line graphics and other symbols. The codes from 155 to 159 are used for international currency symbols.
The 437 character set is shown below:-
The codes from 0 to 31 can produce the special characters as shown, or can be used for standard ASCII control codes, depending on the situation. Code 127 is normally used as a null character, thereby conforming to the ASCII standard, although code 255 can also be used for this function. Other non-standard character sets often employ some of the graphic codes from this set.
ESC 7, consisting of the ESC control code followed by the code for the character 7.ESC 6.This is similar to the above, but has international characters in the place of some graphical elements, allowing almost any Roman-based language to be used.

This is a variation of the ANSI character set, as used with VT220 and other terminals employed for data communications. It uses a special symbol for each control code, such as 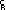 for a
for a CR (carriage return), which means that such codes can be seen within a string of text.

This is yet another communications variation of the ANSI character set, in this instance using special symbols for the control codes. The particular set shown here includes part of the Mac OS character set, as well as other standard characters for use with a VT100 or VT102 terminal:-

Expanded Binary Coded Decimal Interchange Code (EBCDIC) text files are used in IBM mainframe computers and in other mini-computers. A special application is necessary to convert this code into ASCII or Latin-1 form. Unfortunately, not all the codes are entirely standardised.
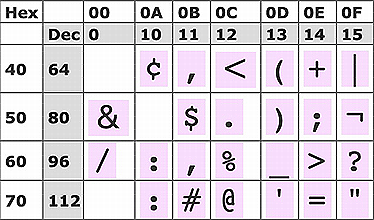
The following tables only show those codes universally employed in the IBM System/360 EBCDIC character set. They begin with the following control codes:-
| Hex | Dec | Name | Function |
|---|---|---|---|
| 00 | 0 | NUL * | Null |
| 01 | 1 | SOH * | Start of heading |
| 02 | 2 | STX * | Start of text |
| 03 | 3 | ETX * | End of text |
| 04 | 4 | PF | Punch off |
| 05 | 5 | HT | Horizontal |
| 06 | 6 | LC | Lower case |
| 07 | 7 | DEL | Delete |
| 0A | 10 | SMM | Start of manual |
| 0B | 11 | VT * | Vertical |
| 0C | 12 | FF * | Form feed |
| 0D | 13 | CR * | Carriage return |
| 0E | 14 | SO * | Shift out |
| 0F | 15 | SI * | Shift in |
| 10 | 16 | DLE | Data link escape |
| 11 | 17 | DC1 * | Device control |
| 12 | 18 | DC2 * | Device control |
| 13 | 19 | DC3 * | Device control |
| 14 | 20 | RES | Restore |
| 15 | 21 | NL | New line |
| 16 | 22 | BS | Back space |
| 17 | 23 | IL | Idle |
| 18 | 24 | CAN * | Cancel |
| 19 | 25 | EM * | End of medium |
| 1A | 26 | CC | Cursor control |
| 1B | 27 | CU1 | Customer use 1 |
| 1C | 28 | IFS * | Interchange |
| 1D | 29 | IGS * | Interchange |
| 1E | 30 | IRS * | Interchange |
| 1F | 31 | IUS * | Interchange |
| 20 | 32 | DS | Digit select |
| 21 | 33 | SOS | Start |
| 22 | 34 | FS | Field separator |
| 24 | 36 | BYP | Bypass |
| 25 | 37 | LF | Line feed |
| 26 | 38 | ETB | End |
| 27 | 39 | ESC | Escape |
| 2A | 42 | SM | Set mode |
| 2B | 43 | CU2 | Customer use 2 |
| 2D | 45 | ENQ | Enquire |
| 2E | 46 | ACK | Acknowledge |
| 2F | 47 | BEL | Bell |
| 32 | 50 | SYN | Synchronous |
| 34 | 52 | PN | Punch in |
| 35 | 53 | RS | Reader stop |
| 36 | 54 | UC | Upper case |
| 37 | 55 | EOT | End of |
| 3B | 59 | CU3 | Customer use 3 |
| 3C | 60 | DC4 | Device |
| 3D | 61 | NAK | Not acknowledge |
| 3F | 63 | SUB | Substitute |
| 40 | 64 | SP | Space |
Standard characters are represented as follows:-

©Ray White 2004.
