
In a computer, each kind of character in a string of text must have its own code. A complete set of characters represented by such codes is known as a character set.
The maximum number of characters in a set is determined by the number of bits that are available for each code. Very early computers only used seven bits for each character, an eighth bit being employed for parity error detection. Unfortunately, such 7-bit coding only accommodated 128 characters, although these were fully standardised and known as the ASCII character set (see below).
Later systems employed more sophisticated error handling, allowing all eight bits to be used for character representation. This newer 8-bit coding accommodated 256 characters, although the codes not defined by ASCII aren’t fully standardised. Finally, there’s 16-bit coding (double-byte coding), providing 65,536 characters, including those used in pictographic languages.
The American Standard for Information Interchange (ASCII) standard was devised for sending data over communications links. It corresponds to the American National Standards Institute (ANSI) standard X34-1986 and is similar to the International Standards Organisation (ISO) specification ISO 646.
In these standards, each character is given a 7-bit code, with a value between 0 and 127. This accommodates 128 characters, usually those printed on a keyboard, as shown below.

Although the set includes all of the usual letters, numbers and punctuation, it unfortunately excludes many non-English or accented characters and other familiar symbols.
£ (pound sign) appears on a British keyboard but actually isn’t in the ASCII character set. On non-British keyboards its place is usually taken by # (hash symbol), which is in the set. To add to the confusion, the hash is often known as a ‘pound’ in the USA.@ (at) is sometimes known as a commercial at or comat.ASCII also defines numbers from 0 to 31 as control codes, each identified by a two or three-letter mnemonic. Examples include HT (Horizontal Tab), CR (carriage return), LF (line feed) and FF (Form Feed). In practice, most applications in the Classic Mac OS shows such characters as a square box ( ), although in some instances they’re also used by the operating system for real-world characters. Many of these codes are often ignored, although some devices use the
), although in some instances they’re also used by the operating system for real-world characters. Many of these codes are often ignored, although some devices use the BEL (Bell) code.
The table below shows how ASCII values are encoded in both decimal and in hex:

Finding the character represented by a number from this kind of table is actually quite easy. For example, suppose you need the character represented by decimal 69. Simply find the row containing the nearest number, 64 in this case, and then move along to a column that increases the value to 69, which in this instance is 5. Hence we deduce that the character is E.
The following tables show the keys used to create these characters in the Classic Mac OS:-

* Not all Mac keyboards can produce these codes
• For a British keyboard: Shift-3 is used in US version of the Mac OS

a comes after both A and Z and that all numbers come before letters. This point is important when you’re sorting text items or filenames.The Mac OS, in common with other modern computer systems, uses 8-bit codes, providing 256 characters in the set, of which 0 to 127 are used for standard ASCII characters. The remainder, 128 to 255, are used for special characters and are coded to match the Mac’s own operating system.
The set used on your machine depends on the script used to represent your language. The following table shows the Mac character sets that are used for each kind of script:-
| Script | Set |
|---|---|
| Western (Roman) | MacRoman |
| Central European | MacCE |
| Arabic | MacArabic |
| Croatian | MacCroatian |
| Cyrillic | MacCyrillic |
| Devanagari | MacDevanagari |
| Farsi | MacFarsi |
| Greek | MacGreek |
| Gujarati | MacGujarati |
| Hebrew | MacHebrew |
| Icelandic | MacIcelandic |
| Romanian | MacRomanian |
| Turkish | MacTurkish |
| Ukrainian | MacUkrainian |
The Roman character set, as used in the Mac OS for western languages, is shown below:-

As you can see, the characters up to 127 (hex 7F) are the same as the standard ASCII character set. In order to obtain some of the extra characters you must press a deadkey followed by a second key. For example, to get the character Ü you must press Option-U followed by Shift-U.
To add to the confusion, some Mac fonts contain non-standard characters. For example, older versions of the Geneva font have a curious sheep character that changes into a rabbit in the larger font sizes.Similarly, some fonts are designed to work as a system font with later versions of the Classic Mac OS, providing the special symbols that appear in pull-down menus. The diagram below shows how such a font uses codes from 1 to 31 to represent such characters:-

whilst the following kind of font, intended for older versions of the Mac OS, uses higher codes:-

The required key combinations for non-ASCII Mac characters are given in the following tables:-
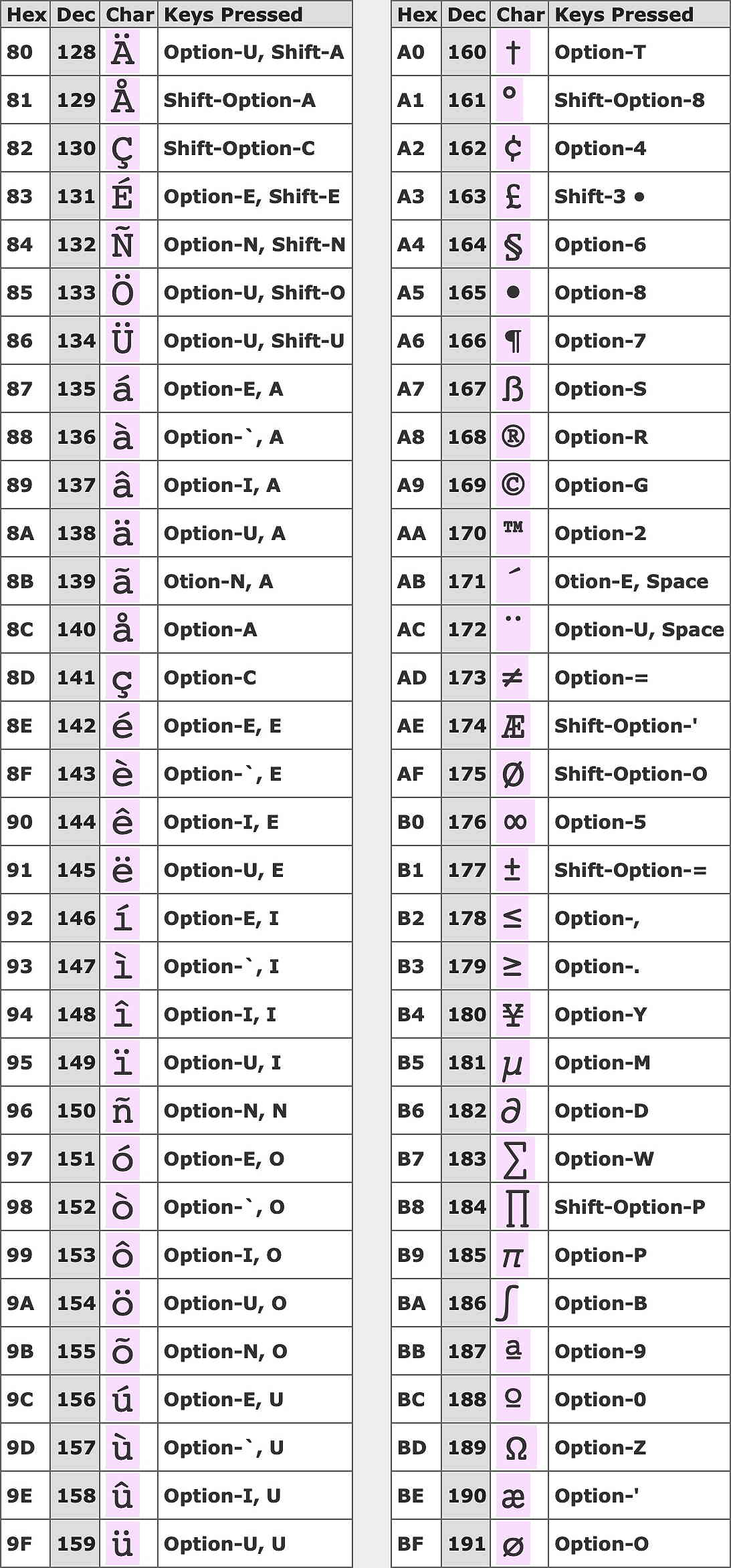
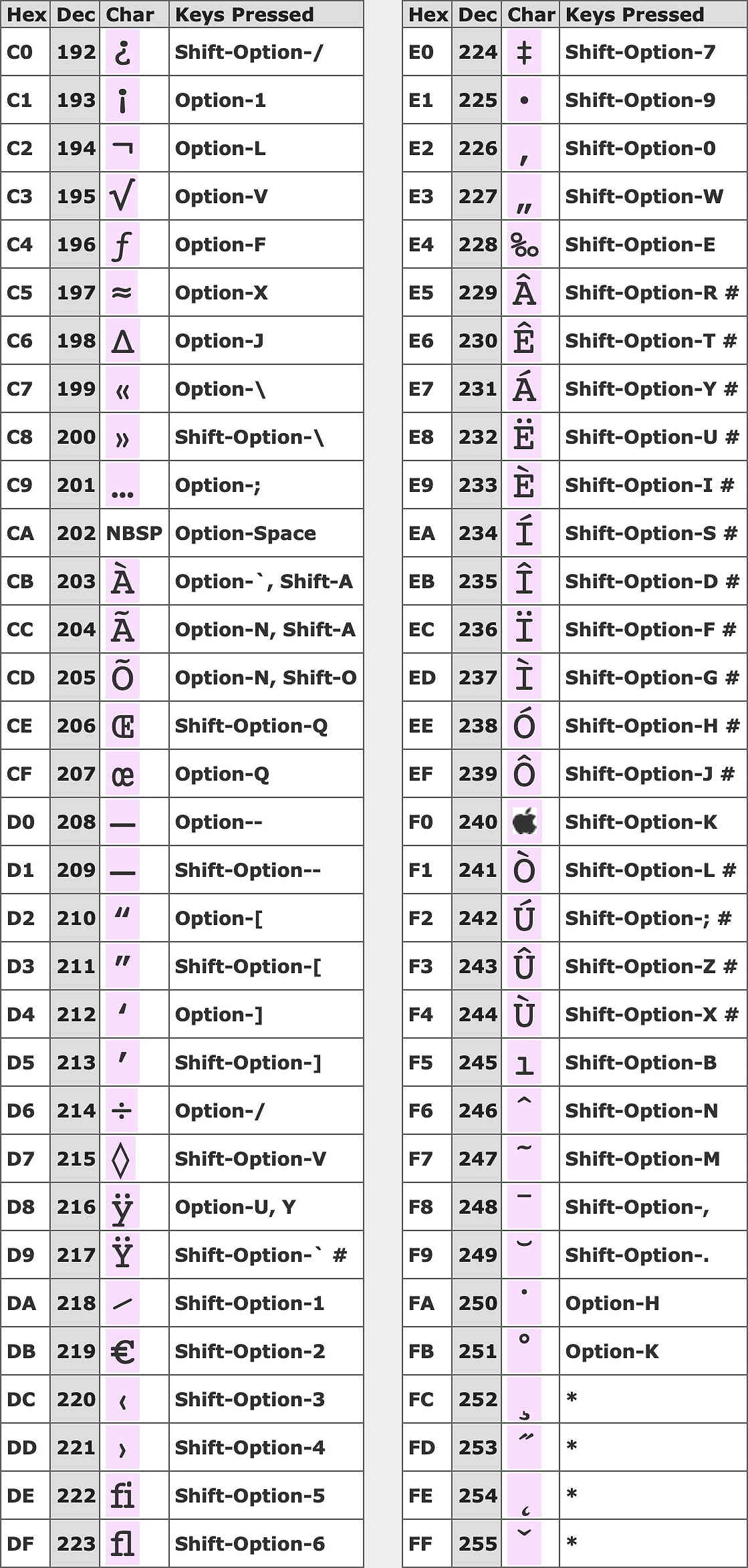
NBSP Non-breaking space
* No key combination available
# Character also available via a deadkey sequence
The Windows operating system also uses its own character sets, as shown in the following table:-
| Script | Set |
|---|---|
| Western | 1252 |
| Central European | 1250 |
| Arabic | 1256 |
| Baltic | 1257 |
| Cyrillic | 1251 |
| Greek | 1253 |
| Hebrew | 1255 |
| Turkish | 1254 |
| Vietnamese | 1258 |
Most western countries, excluding central Europe, employ the Windows 1252 set, which is essentially based on the ISO 8859-1 standard (see below). The 1252 character set is shown below:- 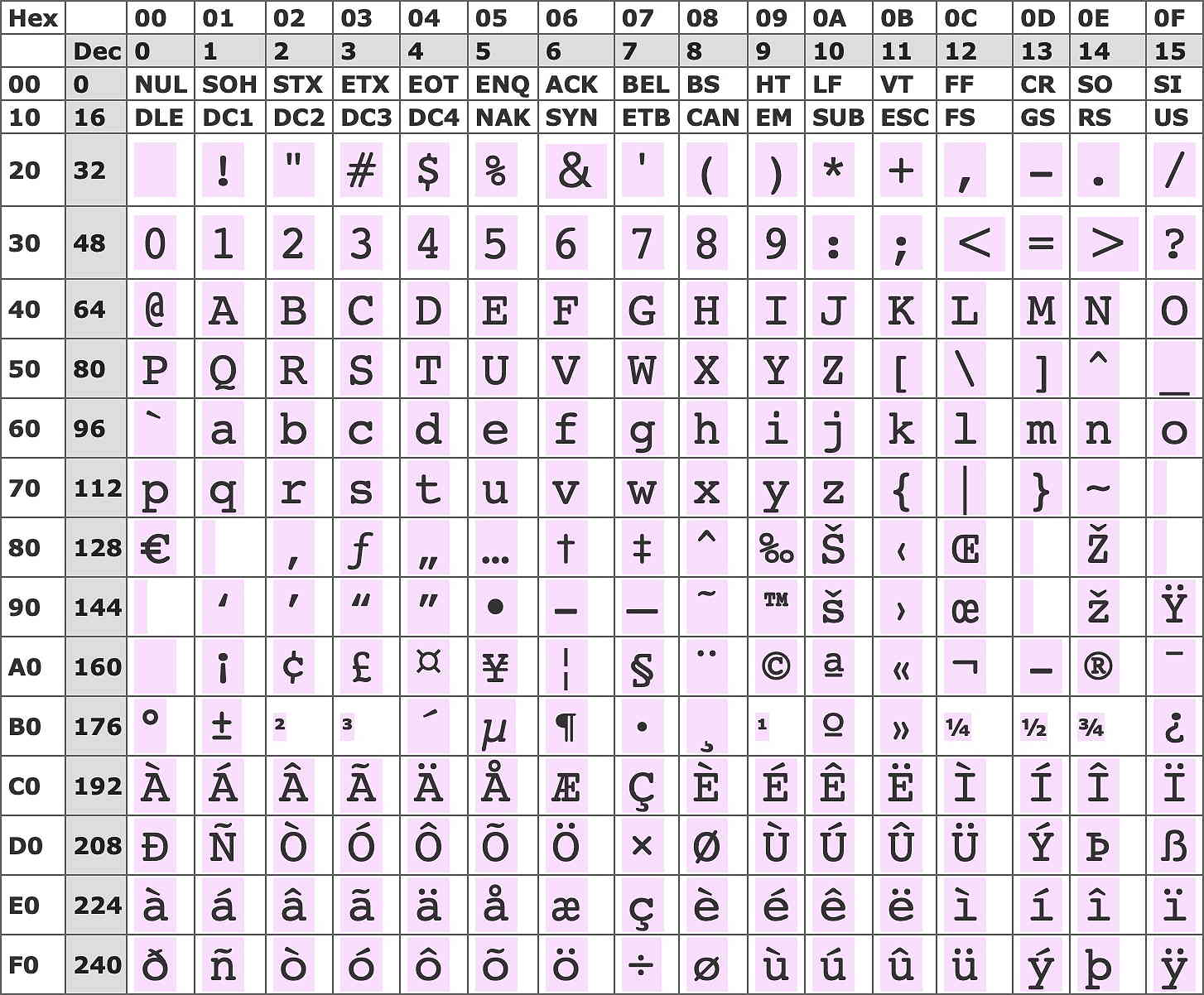
The International Standards Organisation (ISO) has defined several 8-bit character sets, mainly intended for transferring textual information between different computer platforms. The common ISO 8859 standard defines the following character sets:-
| Script | Set |
|---|---|
| Western | ISO-8859-1 |
| Western | ISO-8859-15 |
| Central European | ISO-8859-2 |
| South European | ISO-8859-3 |
| Arabic | ISO-8859-6 |
| Baltic | ISO-8859-4 |
| Baltic | ISO-8859-13 |
| Celtic | ISO-8859-14 |
| Cyrillic | ISO-8859-5 |
| Greek | ISO-8859-7 |
| Hebrew | ISO-8859-8-1 |
| Hebrew (Visual) | ISO-8859-8 |
| Nordic | ISO-8859-10 |
| Turkish | ISO-8859-9 |
The ISO 8859-1 character set, also known as the Latin-1 set, is employed to represent the characters in many western languages, excluding those of central Europe. Fortunately, this set is basically the same as Windows 1252 (see above), although the codes from 128 to 159 aren’t included in the standard, since they’re commonly used in alternative character sets, as shown below:-

These values should always be avoided when using ISO 8859-1 coding. Instead, the characters represented by these codes must be conveyed using 16-bit values, usually in the form of Unicode.
©Ray White 2004.
