
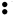

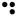

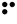
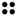







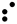
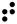


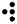




Data, in the context of this document, consists of ‘real world’ information that has been coded into a form that can be transmitted and received by modern electronic devices.
Early systems can convey text as a string of characters, with the most commonly-used letters identified by the simplest codes. For example, Morse code, as used for sending messages over a telegraphic circuit or via a radio transmitter, gives precedence to letters in the following order:-
Similarly, the original Linotype printing system, is based on the following order:-
The standard QWERTY keyboard, however, was planned with entirely the opposite objective in mind, since early keyboard mechanisms had a nasty propensity for jamming.
This code allows a single wire to carry useful data over a single telegraphic circuit. Such a wire can be set to one of two logical voltages, indicating either on, corresponding to logical 1, or off, corresponding to logical 0. This means that the data must be sent as a series of on and off pulses.
The human recipient of a Morse message must be able to recognise these pulses, as reproduced by a sounder. Morse himself realised that sequences of fixed width pulses couldn’t be easily identified, so he hit upon the idea of using both short pulses (dots) and long pulses (dashes). In effect, he had created a tri-state system, with off as the rest condition and data in the form of a dot or dash.
The following table shows the standard codes, which are of a variable length:-
| Morse Code | |||
|---|---|---|---|
| A | · — | B | — · · · |
| C | — · — · | D | — · · |
| E | · | F | · · — · |
| G | — — · | H | · · · · |
| I | · · | J | · — — — |
| K | — · — | L | · — · · |
| M | — — | N | — · |
| O | — — — | P | · — — · |
| Q | — — · — | R | · — · |
| S | · · · | T | — |
| U | · · — | V | · · · — |
| W | · — — | X | — · · — |
| Y | — · — — | Z | — — · · |
| - | — · · · · — | ’ | · — — — — · |
The Braille system allows blind people to read textual material, which is presented as an arrangement of dots that can be felt using the fingers. As with Morse code, a unique pattern is used for each character, as shown in the following table:-
| Braille | |||||||
|---|---|---|---|---|---|---|---|
| A | | B | | C | | D | |
| E | | F | | G | | H | |
| I | | J | | K | | L | |
| M | | N | | O | | P | |
| Q | | R | | S | | T | |
| U | | V | | W | | X | |
| Y | | Z | | - | | ||
Unlike Morse code and other early forms of coding, which have to be recognised by people, the data travelling around inside a computer only needs to be understood by the machine itself, so all the characters are treated as being equally important. In addition, a computer can use more than one wire to convey information: typically, a machine employs 8, 16, 32 or 64 wires in a bus of wires.
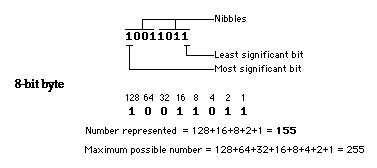
Each wire in a bus represents a binary digit (bit). Each of these bits is given a value or weighting of 1, 2, 4, 8 and so on. A binary term or byte, also known as an octet, contains eight of these bits, corresponding to the 8-bit buses found in early computers. Despite this, most modern machines employ 16-bit, 24-bit or 32-bit data and address buses.
The alphanumeric characters in text can be represented by a single byte, although the pictographic characters used for Asian languages such as Japanese, Chinese and Korean require double-byte coding. Of course, a byte can also convey other kinds of information, such as half a sample of 16-bit digital audio or part of the representation of a picture.
The contents of a byte or word can be expressed in binary notation, containing just ones and zeros, as shown below:-
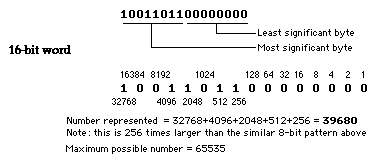
The number of bits conveyed by a system are best measured using the following terms:-
| Term | Value | |
|---|---|---|
| 1 bit (1B) | 1 | 20 |
| 1 kibibit (kibit) | 1,024 | 210 |
| 1 mebibit (Mibit) | 1,048,576 | 220 |
| 1 gibibit (Gibit) | 1,073,741, | 230 |
| 1 tebibit (Tibit) | 1,099,511, | 240 |
| 1 pebibit (Pibit) | 1,125,899, | 250 |
| 1 exbibit (Eibit) | 1,152,921, | 260 |
| 1 zebibit (Zibit) | 1,180,591, | 270 |
| 1 yobibit (Yibit) | 1,208,925, | 280 |
| 1 nobibit (Nibit) | 1.237940 | 290 |
| 1 dogbibit (Dibit) | 1.267650 | 2100 |
These contain binary multipliers, as indicated by the letters bi in the name and the letter i in the multiplier’s abbreviation. The following alternative terms, often confused or interchanged with the above, are frequently used:-
| Term | Value |
|---|---|
| 1 bit | 100 (1) |
| 1 kilobit (kbit) | 103 (1,000) |
| 1 megabit (Mbit) | 106 (1,000,000) |
| 1 gigabit (Gbit) | 109 |
| 1 terabit (Tbit) | 1012 |
| 1 petabit (Pbit) | 1015 |
| 1 exabit (Ebit) | 1018 |
| 1 zettabit (Zbit) | 1021 |
| 1 yottabit (Ybit) | 1024 |
| 1 nonabit (Nbit) | 1027 |
| 1 doggabit (Dbit) | 1030 |
The size of a computer’s memory or disk drive can be measured in bytes or multiples of bytes, as shown in the table below. Each byte normally contains only eight bits, even though the computer system may use 64 bits or more for computations. The multipliers shown in the following table work in exactly the same way as those used for bits.
| Term | Value | |
|---|---|---|
| 1 byte | 1 | 20 |
| 1 kibibyte | 1,024 | 210 |
| 1 mebibyte | 1,048,576 | 220 |
| 1 gibibyte | 1,073,741, | 230 |
| 1 tebibyte | 1,099,511, | 240 |
| 1 pebibyte | 1,125,899, | 250 |
| 1 exbibyte | 1,152,921, | 260 |
| 1 zebibyte | 1,180,591, | 270 |
| 1 yobibyte | 1,208,925, | 280 |
| 1 nobibyte | 1.237940 | 290 |
| 1 dogbibyte | 1.267650 | 2100 |
The standard terms shown above one again involve binary multipliers, as indicated by the letters bi in the name and the letter i in the multiplier’s abbreviation. The alternative terms shown below are often used in error, and actually refer to the decimal multipliers of System International (SI) units:-
| Term | Value |
|---|---|
| 1 byte | 100 (1) |
| 1 kilobyte (kbyte) | 103 (1,000) |
| 1 megabyte (Mbyte) | 106 (1,000,000) |
| 1 gigabyte (Gbyte) | 109 |
| 1 terabyte (Tbyte) | 1012 |
| 1 petabyte (Pbyte) | 1015 |
| 1 exabyte (Ebyte) | 1018 |
| 1 zettabyte (Zbyte) | 1021 |
| 1 yottabyte (Ybyte) | 1024 |
| 1 nonabyte (Nbyte) | 1027 |
| 1 doggabyte (Dbyte) | 1030 |
These terms can be misleading, as it’s often, and wrongly, assumed that they have binary multipliers.
K, as in KB, sometimes indicates the larger binary-based value of 1024 bytes, whilst a lowercase k, as in kB, indicates the decimal-based value of 1000 bytes.To see the above in context, it’s useful to understand that one megabyte conveys around 179 thousand real words in the English language. It’s also worth noting that modern technology rarely goes beyond a terabyte, although some systems allow for future storage capacities in the realm of exabytes. The following table attempts to give some meaning to these values:-
| Term | Information | |
|---|---|---|
| 1 byte | 1 B | 8 bits or |
| 1 kilobyte | 1 KB | Very |
| 1 megabyte | 1 MB | Small |
| 1 gigabyte | 1 GB | Text |
| 1 terabyte | 1 TB | Text |
| 1 petabyte | 1 PB | Half |
| 1 exabyte | 1 EB | One |
It’s also worth noting that the printed collection of the US Library of Congress would occupy 10 terabytes, whilst the human brain stores 11.5 terabytes in its lifetime, the equivalent of around 100 trillion bits or 12 million megabytes.
Hexadecimal or hex is a shorthand notation used by programmers to represent binary numbers. Each group of 4 bits or half a byte, also known as a nibble, is represented by a single hex digit.
In each digit, 0 to 9 represent the numbers 0 to 9, as in decimal numbers, whilst the letters A to F are used for 10 to 15. Hence decimal 14 is represented as E or 0E in hex. The diagram below shows how a byte-sized binary number is represented in hex:-
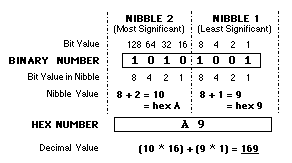
This also shows how easy it is to convert hex back into decimal or binary. It’s worth remembering that the second nibble is 16 times larger than the first. Similarly, a third nibble would be 16 times larger than the second, or 256 times larger than the first, and so on.
40, 80 and FF respectively.ß (the German double-S). Hence hex E3C00000 is written as E3Cß.When data is transferred to and from various systems it should be checked to avoid data corruption. Sometimes, such a check only uses error detection to tell you that something is wrong, although other methods can provide error correction that rectifies any damage caused to the data.
In this method, a special number, known as a checksum, is calculated from each block of data in a file and a chosen polynomial coefficient. This checksum accompanies the data on its journey and is then compared with a second checksum generated from the received data. All being well, both checksums should be identical and the file can be accepted as being uncorrupted.
sum-r command in System V.Additional processing of checksums can be used to increase file security. For example, if you use the RSA Data Security Message-Digest Algorithm (RSA MD5), any small change in the source file will cause a large change in the checksum. MD5 uses a 128-bit signature for each file.
Cyclic redundancy check methods are used for the superior error detection algorithms detailed below. Many of these are based on standards established by the International Telephone and Telegraph Consultative Committee (CCITT).
CCITT 16: a standard system defined by the CCITT.
Polynomial Coefficients: x16 + x12 + x5 + 1
Coefficient in hex: 1021
Initial Value: -1
Byte Order: Normal
CRC 16: a proprietary system used in Arc and similar applications.
Polynomial Coefficients: x16 + x15 + x2 + 1
Coefficient in hex: A001
Initial Value: 0
Byte Order: Swapped
CCITT 32: a standard system defined by the CCITT.
Polynomial Coefficients: x32 + x26 + x23 + x22 + x16 + x12 + x11 + x10 + x8 + x7 + x5 + x4 + x2 + x + 1
Coefficient in hex: 04C11DB7
Initial Value: -1
Byte Order: Normal
POSIX.2: similar to CCITT 32, but as used in the POSIX.2 cksum utility.
Polynomial Coefficients: x32 + x26 + x23 + x22 + x16 + x12 + x11 + x10 + x8 + x7 + x5 + x4 + x2 + x + 1
Coefficient in hex: 04C11DB7
Initial Value: -1
Byte Order: Normal
Zip 32: as used in Zip, Compact Pro and other commercial applications.
Polynomial Coefficients: x32 + x31 + x30 + x29 + x27+ x26 + x24 + x23 + x21 + x20 + x19 + x15 + x9 + x8 + x5
Coefficient in hex: EDB88320
Initial Value: -1
Byte Order: Swapped
Coefficient in hex is a value that represents the polynomial as a bitmap.The values used in a computer can be broadly divided into numbers and strings. Numbers usually have values within a specified range whilst strings, most commonly used to represent textual information, are frequently of an indeterminate length.
An integer is a numerical value that has no fractional part, such as 34 or 129. Such numbers can be conveniently represented by one or two bytes, as shown below:-
| Type | 1 byte | 2 byte |
|---|---|---|
| Unsigned | 0 to | 0 to 65,535 |
| Signed | -128 to | -32,768 to |
The code for a negative signed integer is obtained using the two’s complement method. Larger numbers, signed or unsigned, can be represented by a long word, usually containing 32 bits or more, although it’s better to use a floating point value (see below).
1234 as 3412, with the value 34 kept in the lowest address. This system is sometimes known as back-words storage.Floating point numbers, also known as real numbers or temporary real numbers, are values that contain both a whole number and a fractional part, such as 3.4 or 96.12. Each value of this kind can be represented using several bytes, as shown below:-
| Number of | Decimal Digits |
|---|---|
| 4 | 6 |
| 8 | 16 |
| 10 | 18 |
The different degrees of accuracy are known as single-precision and double-precision.
A maths co-processor or floating point unit (FPU) is often required for fast floating-point calculations. Older 680x0-based Macs sometimes use a 68882 FPU whilst some PCs have a numeric data processor (NDP). The original PC processes 10-byte values, contains constants such as π and can perform standard maths operations such as addition, subtraction, multiplication and division, as well as transcendental operations for trigonometric and logarithmic calculations.
A string consists of any textual characters or punctuation that can be printed, such as:-
Each character or item of punctuation within such text is represented by a specific character code. Numbers can be interposed within the data to keep track of each string items’s length, as in:-
Unfortunately, if these numbers are 8-bit unsigned integers (see above) the maximum length of any string is limited to 255 characters. A similar restriction applies to text displayed in older versions of the Mac OS, and also applies to standard dialogue boxes in this system. Using 16-bit signed integers increases the maximum text to 32 KB, a limit that’s often encountered in the Classic Mac OS, particularly in Apple’s SimpleText application.
Computers usually store the first character of a string at the lowest address in it’s memory. For example, the code for F in the string Fred is normally kept at the lowest address, whilst the codes for the remaining characters are placed at higher locations.
All modern computers contain a clock that keeps track of the actual date and time, even when the machine isn’t running. Whenever you create or modify a file the document’s creation date (and time) and/or modification date (and time) is set to the current date and time.
Many computer platforms use proprietary systems to record date and time information. The simplest date systems involve a record of the day number, month number and year number, as, for example, in 31/05/2004. This can then be interpreted into a form to suit the local language and calendar, such as 31 May, 2004 for British users or May 31, 2004 for those in the USA.
Dates in this form often involve the use of a 5-bit day code, a 4-bit month code and a 12-bit year code, as shown in the following examples:-
| Date | Binary Codes |
|---|---|
| 31 | 11111 1100 011111111111 |
| 1 | 00001 0001 100000000000 |
Unfortunately, such date systems are too ‘tied in’ to the Western calendar system. The Classic Mac OS takes a different approach, measuring date and time as the number of seconds elapsed since January 1st, 1904. The whole number part shows the number of days that have passed, so giving the date. The fractional part, to the right of the decimal point, indicates the actual time of day. This mechanism was designed to last until 2040 but has been extended in later versions of the system.
Older PC software and some hardware is based on a 2-digit year number, as in 31/09/98, where 98 represents the year 1998. Due to an amazing lack of foresight, no-one thought too much about what would happen in the year 2000, when many devices might well revert to the year 1900.
This problem (which wasn’t as bad as expected) is solved by replacing system and application software by Year 2000 Compliant (Y2KC) versions, which use a 4-digit year number, as described above. Other microprocessor-based devices, especially those in crucial areas of public services, can be more difficult to fix, often requiring modifications or entirely new equipment.
1972. Not a perfect solution, but practical for many purposes.The actual calendar system that’s used for measuring days, months and years varies with countries and cultures. Fortunately, most computer platforms automatically convert the existing date values to the appropriate calendar once you’ve selected your own country in the system software.
Most businesses also use week numbers. The ISO standard specifies that Week 1 should be the first week that contains four or more days of the new year.
The clock in a computer at a fixed location is normally set to the local time used in that area. Complications occur with a portable computer, however, since the world is divided into various time zones, in which local clocks are set so that the sun is near the middle of the sky at 12 am.
To avoid this problem, many organisations employ some form of global time, which remains the same at every location. The most common standard is Greenwich Mean Time (GMT), which is measured in London on the line of longitude known as the Greenwich meridian.
The problems with time zones are exacerbated by the use of daylight saving, a mechanism used in many countries to ensure that the available hours of daylight are used to best advantage during darker months of the year. This is particularly useful in countries at higher degrees of latitude. The process normally involves moving the clocks by an hour in the spring and moving them back again in the autumn. Unfortunately, not all countries are able to use the same dates or offsets.
2 am in the morning on the last Sunday in March and ceases at the same time on the last Sunday in October.Suppose you were in London, created a number of files and then flew to the USA. If you were then to adjust the machine’s clock to the local time in the States you might discover that the files you saved in London were actually created a couple of hours in the future. Worse still, this could cause your file synchronisation utility to backup the wrong files.
Some operating systems, such as later versions of Mac OS, overcome this by storing all time information in global form, in this instance GMT. The operating system then presents the time according to a chosen location name. The user can then select, for example, London or New York, to suit the current location, allowing the computer to display all times in relation to the appropriate time zone. Furthermore, the machine can automatically adjust the click to suit local daylight saving.
ConvertStuff Help, © 2004, Lewis Story
©Ray White 2004-2021.
